linux文本处理三剑客
awk、grep、sed是linux操作文本的三大利器,合称文本三剑客,也是必须掌握的linux命令之一。三者的功能都是处理文本,但侧重点各不相同,其中属awk功能最强大,但也最复杂。
grep更适合单纯的查找或匹配文本,sed更适合编辑匹配到的文本,awk更适合格式化文本,对文本进行较复杂格式处理。
grep
什么是grep和egrep
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来(匹配到的标红)。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
egrep = grep -E:扩展的正则表达式 (除了< , > , \b 使用其他正则都可以去掉\)
正则推荐学习网站:https://regexlearn.com/zh-cn
使用grep
grep命令格式
1 | grep [option] pattern file |
命令参数
- -A<显示行数>:除了显示符合范本样式的那一列之外,并显示该行之后的内容。
- -B<显示行数>:除了显示符合样式的那一行之外,并显示该行之前的内容。
- -C<显示行数>:除了显示符合样式的那一行之外,并显示该行之前后的内容。
- -c:统计匹配的行数
- -e :实现多个选项间的逻辑or 关系
- -E:扩展的正则表达式
- -f FILE:从FILE获取PATTERN匹配
- -F :相当于fgrep
- -i –ignore-case #忽略字符大小写的差别。
- -n:显示匹配的行号
- -o:仅显示匹配到的字符串
- -q: 静默模式,不输出任何信息
- -s:不显示错误信息。
- -v:显示不被pattern 匹配到的行,相当于[^] 反向匹配
- -w :匹配 整个单词
实例
1 | # 准备一个测试文件 |
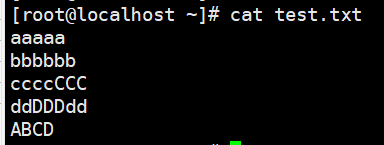
1 | # 显示匹配到的b的那一行,并显示后面2行 |
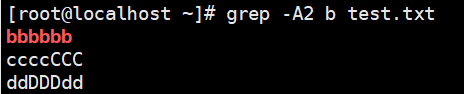
1 | # 显示匹配到b的那一行,并显示之前1行 |

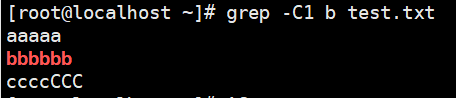
1 | # 显示匹配到b的那一行,并显示前后1行 |
1 | # 统计匹配到的行数 |

1 | # 实现多个选项间的逻辑or关系 |

1 | # 从FILE获取PATTERN匹配 |

1 | # -i --ignore-case #忽略字符大小写的差别 |

1 | # -n:显示匹配的行号 |

1 | # -o:仅显示匹配到的字符串 |

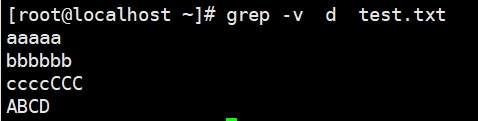
1 | # -v:显示不被pattern 匹配到的行,相当于[^] 反向匹配 |
1 | # -w :匹配 整个单词 |

补充
一般我们使用grep都是配合管道符号 |使用的 比如查看nginx进程,
1 | # 查看nginx进程,判断nginx是否开启 |

1 | # 查看80端口是否被占用 |

sed
什么是sed
sed 是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(patternspace ),接着用sed 命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。然后读入下行,执行下一个循环。如果没有使诸如‘D’ 的特殊命令,那会在两个循环之间清空模式空间,但不会清空保留空间。这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出或-i。
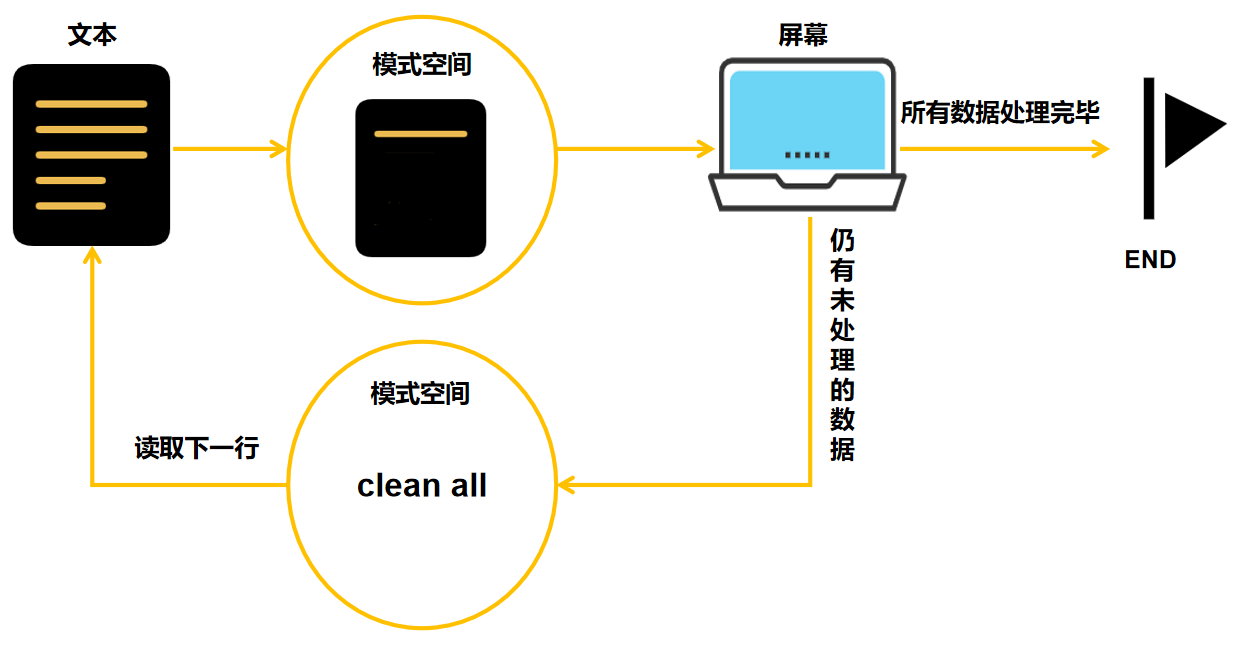
功能:主要用来自动编辑一个或多个文件, 简化对文件的反复操作
sed的使用
命令格式
1 | sed [options] '/pattern/ command' file(s) |
常用选项options
- -n:不输出模式空间内容到屏幕,即不自动打印,只打印匹配到的行
- -e:多点编辑,对每行处理时,可以有多个Script
- -f:把Script写到文件当中,在执行sed时-f 指定文件路径,如果是多个Script,换行写
- -r:支持扩展的正则表达式
- -i:直接将处理的结果写入文件
- -i.bak:在将处理的结果写入文件之前备份一份
编辑命令command
- d:删除模式空间匹配的行,并立即启用下一轮循环
- p:打印当前模式空间内容,追加到默认输出之后
- a:在指定行后面追加文本,支持使用\n实现多行追加
- i:在行前面插入文本,支持使用\n实现多行追加
- c:替换行为单行或多行文本,支持使用\n实现多行追加
- w:保存模式匹配的行至指定文件
- r:读取指定文件的文本至模式空间中匹配到的行后
- =:为模式空间中的行打印行号
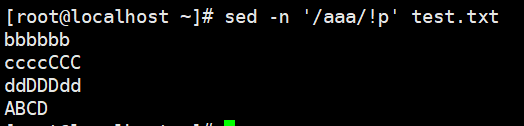
- !:模式空间中匹配行取反处理
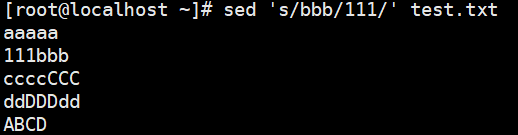
- s///:查找替换,支持使用其它分隔符,如:s@@@,s###;
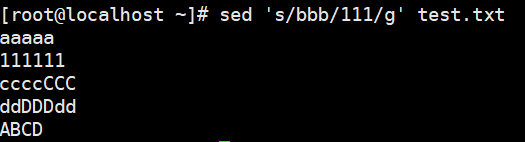
- 加g表示行内全局替换;
- 在替换时,可以加一下命令,实现大小写转换
- \l:把下个字符转换成小写。
- \L:把replacement字母转换成小写,直到\U或\E出现。
- \u:把下个字符转换成大写。
- \U:把replacement字母转换成大写,直到\L或\E出现。
- \E:停止以\L或\U开始的大小写转换
sed实例
1 | # 还是那个测试文件 |
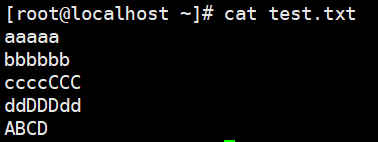
1 | # p:匹配到的行会打印一遍,不匹配的行也会打印 |
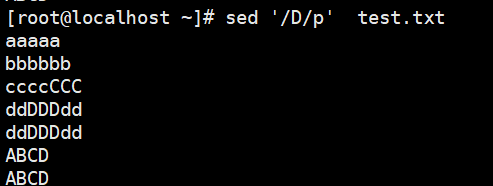
1 | # -n:不输出模式空间内容到屏幕,即不自动打印,只打印匹配到的行 |

1 | # -e:多点编辑,对每行处理时,可以有多个Script |

1 | # -f:把Script写到文件当中,在执行sed时-f 指定文件路径,如果是多个Script,换行写 |

1 | # a:在指定行后面追加文本,支持使用\n实现多行追加 |
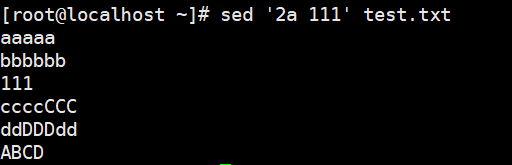
1 | # i:在行前面插入文本,支持使用\n实现多行追加 |
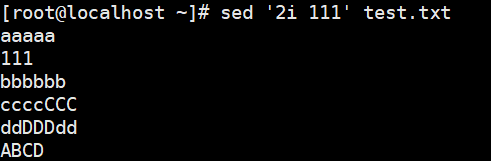
1 | # c:替换行为单行或多行文本,支持使用\n实现多行追加 |
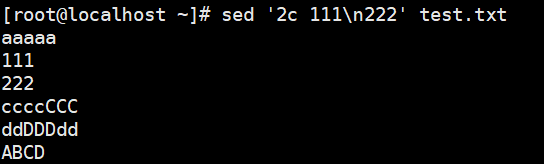
1 | # w:保存模式匹配的行至指定文件 |
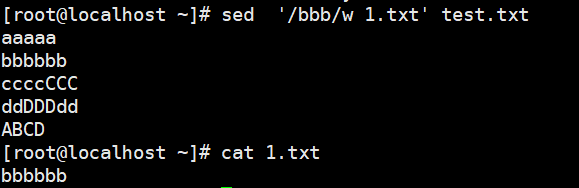
1 | # r:读取指定文件的文本至模式空间中匹配到的行后 |
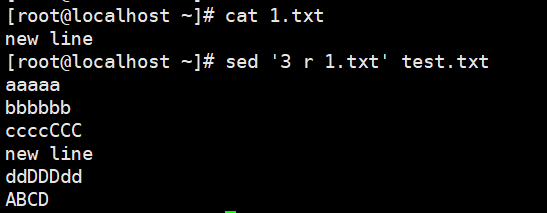
1 | # =:为模式空间中的行打印行号 |
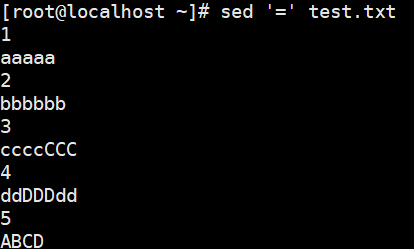
1 | # !:模式空间中匹配行取反处理 |
1 | # s///:查找替换,支持使用其它分隔符,如:s@@@,s###; |
1 | # 加g表示行内全局替换; |
awk
什么是awk
awk是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。awk有很多内建的功能,比如数组、函数等,这是它和C语言的相同之处,灵活性是awk最大的优势。
awk其实不仅仅是工具软件,还是一种编程语言。不过,本文只介绍它的命令行用法,对于大多数场合,应该足够用了。
awk的使用
命令格式
1 | awk [options] 'script' var=value file(s) |
常用命令选项
- -F fs fs指定输入分隔符,fs可以是字符串或正则表达式,如-F:
- -v var=value 赋值一个用户定义变量,将外部变量传递给awk
- -f scripfile 从脚本文件中读取awk命令
语法结构
awk是由pattern和action组成, pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令.
1 | awk '{pattern + action}' {filenames} |
pattern 可以是如下几种或者什么都没有(全部匹配):
- /正则表达式/:使用通配符的扩展集。
- 关系表达式:使用运算符进行操作,可以是字符串或数字的比较测试。
- 模式匹配表达式:用运算符
(匹配)和!(不匹配)。 - BEGIN语句块、pattern语句块、END语句块:参见awk的工作原理
action 由一个或多个命令、函数、表达式组成,之间由换行符或分号隔开,并位于大括号内,可以是如下几种,或者什么都没有(print)
- 变量或数组赋值
- 输出命令
- 内置函数
- 控制流语句
awk常见应用和工作原理
下面列出一个最常用的awk命令结构,借此分析原理
1 | awk 'BEGIN{ commands } pattern{ commands } END{ commands }' |
- 首先执行
BEGIN {commands}内的语句块,注意这只会执行一次,经常用于变量初始化,头行打印一些表头信息,只会执行一次,在通过stdin读入数据前就被执行; - 从文件内容中读取一行,注意awk是以行为单位处理的,每读取一行使用
pattern{commands}循环处理 可以理解成一个for循环,这也是最重要的部分; - 最后执行
END{ commands },也是执行一次,在所有行处理完后执行,一帮用于打印一些统计结果。
实例:
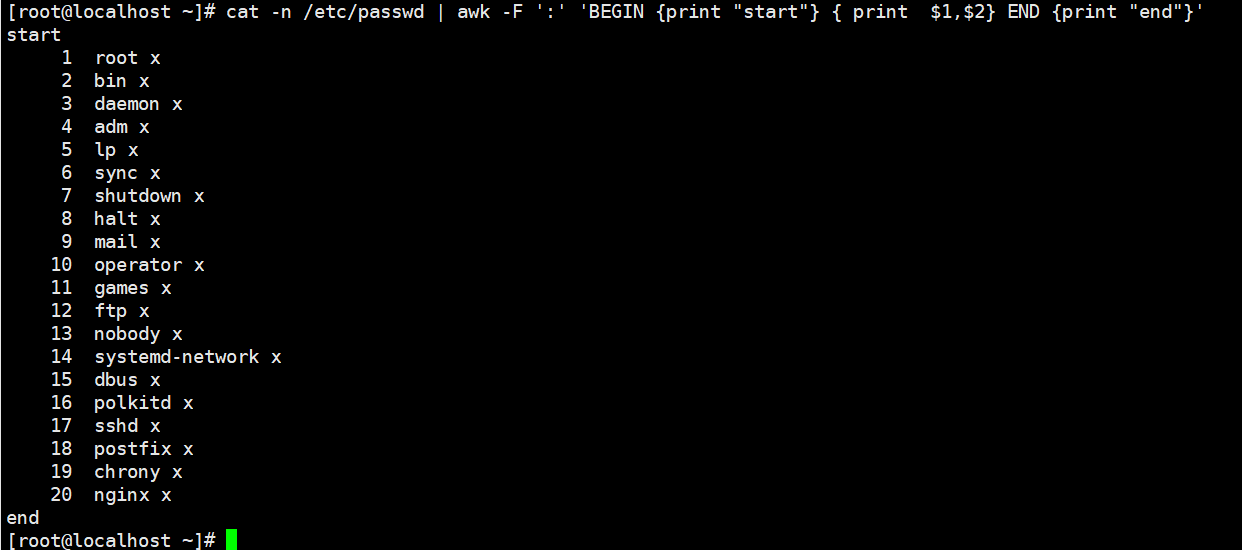
1 | cat -n /etc/passwd | awk -F ':' 'BEGIN {print "start"} { print $1,$2} END {print "end"}' |
awk的内置变量
- FS :输入字段分隔符,默认为空白字符
1 | head -n 5 passwd.bak | awk -v FS=':' '{print $1,$2}' |

- OFS :输出字段分隔符,默认为空白字符
1 | head -n 5 passwd.bak | awk -v FS=':' -v OFS='----' '{print $1,$2}' |

- RS :输入记录分隔符,指定输入时的换行符,原换行符仍有效,原来是以
\n作为行分隔符
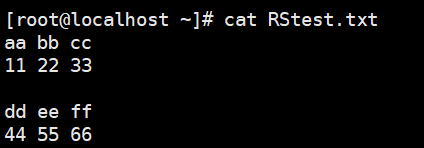
1 | # 查看测试文件 |
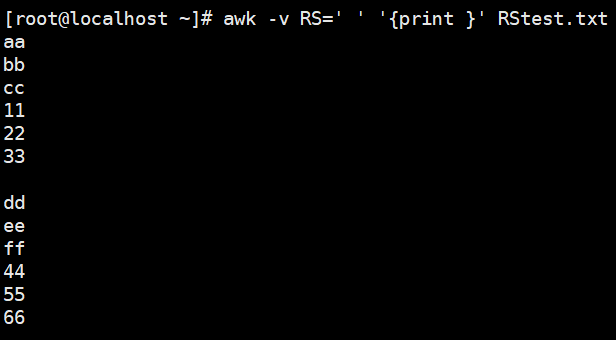
1 | # 以空格为行分隔符 |
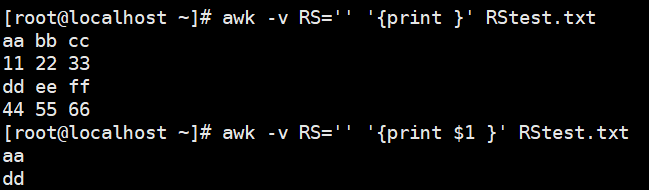
1 | # 以段落为分隔符 |
- ORS :输出记录分隔符,输出时用指定符号代替换行符
1 | # 输出的时候不再用原来的`\n` 而是改成指定的 |

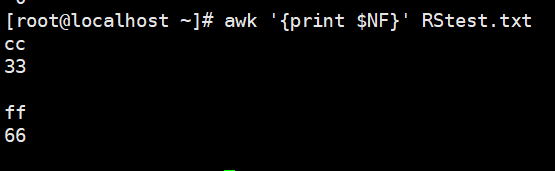
- NF :字段数量,共有多少字段, $NF引用最后一列,$(NF-1)引用倒数第2列
1 | # NF显示字段数量 |
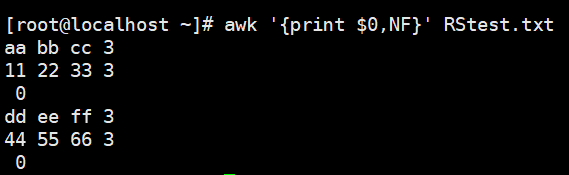
1 | # $NF引用最后一列 |
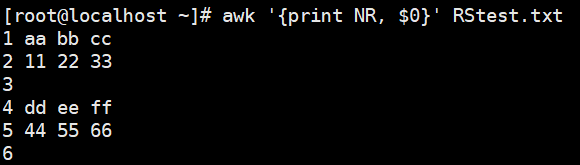
- NR :行号,后可跟多个文件,第二个文件行号继续从第一个文件最后行号开始
1 | # 显示行号 |
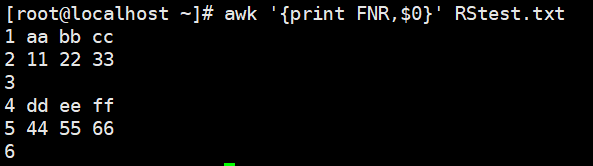
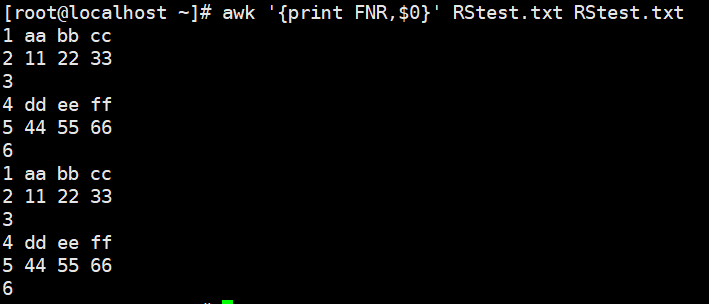
- FNR :各文件分别计数, 行号,后跟一个文件和NR一样,跟多个文件,第二个文件行号从1开始 单个文件与NR没区别
1 | awk '{print FNR,$0}' RStest.txt |
1 | awk '{print FNR,$0}' RStest.txt RStest.txt |
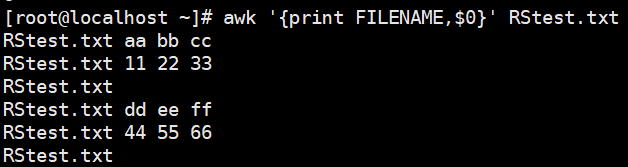
- FILENAME :当前文件名
1 | awk '{print FILENAME,$0}' RStest.txt |
ARGC :命令行参数的个数
ARGV :数组,保存的是命令行所给定的各参数,查看参数
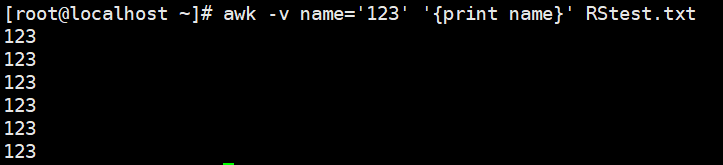
自定义变量
1 | # 用-v 自义定变量 |
常用实例
1 | # 在 a b c d 的b 后面插入新字段 e f g |

1 | # 从ifconfig命令的结果中筛选出除了lo网卡外的所有IPV4地址. |

1 | # 读取配置文件中的某一段配置 |
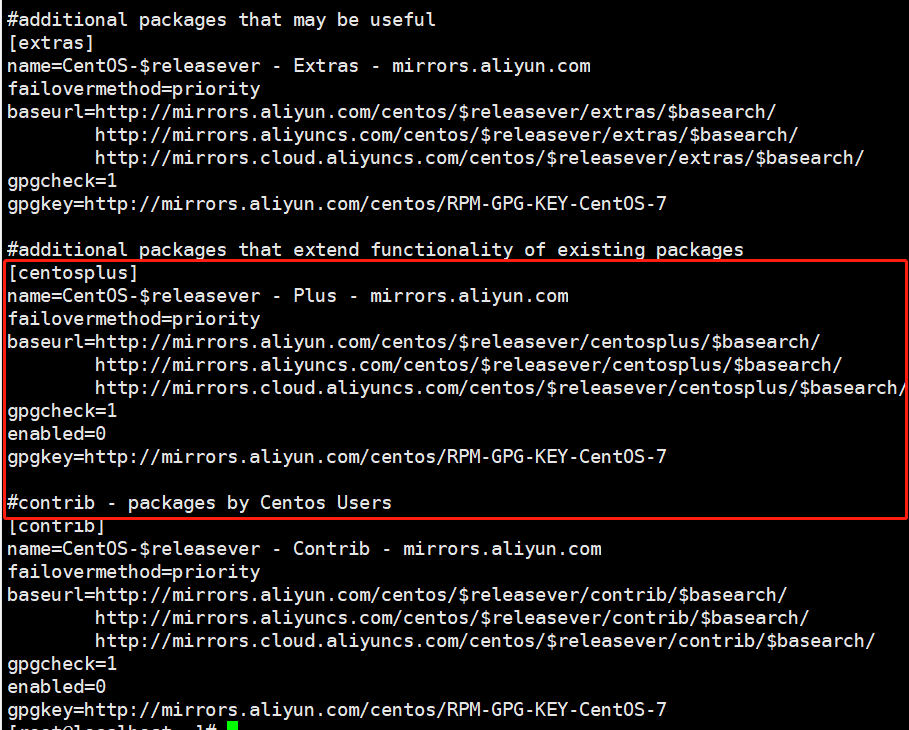
1 | vim 1.awk |
1 | awk -f 1.awk /etc/yum.repos.d/CentOS-Base.repo |
1 | # 去重 |

1 | # 统计数量 |
1 | # 取字段中的指定字段数量 |
